CLAUDE.md was cobbled together from two posts — a Reddit thread by u/Playful-Sport-448 and a Medium article by Scott Waddell. I adopted both nearly verbatim, combined them, and called it done.
It helped, but not enough. The phrasing was vague, some sections contradicted each other, and I suspected parts were actively working against what I wanted. So I decided to do this properly: research what the community had actually tried, understand why things worked or didn’t, and rebuild from first principles.
I brought Claude in for the research. We worked through ten sources — GitHub issues, blog posts, research papers, public CLAUDE.md repositories. The range is instructive.

What the Community Has Tried
u/Playful-Sport-448 (Reddit, r/ClaudeAI) wrote the post I’d based my original CLAUDE.md on. The prompt is clean and well-structured: “intellectual honesty”, “critical engagement”, “what to avoid.” It’s the template hundreds of people have adopted, and where most people start.
Scott Waddell (Medium) coined the “sparring partner behavioral spec” framing and introduced the before/after Response Framework — concrete Good/Bad examples showing what you want, not just describing it. This is the most imitated pattern in the space, and the most effective element in any of the prompts we reviewed.
GitHub Issue #3382 — “Claude says ‘You’re absolutely right!’ about everything” — has 874 upvotes. Filed as a bug. The thread includes a community-authored CLAUDE.md block with explicit phrasing prohibitions and replacement examples. Multiple replies describe it as partially effective at best, even with IMPORTANT flags.
The claude-emotion-prompting repository translates Anthropic’s 2026 mechanistic research on emotion vectors into practical prompting tools. The most theoretically grounded source we found, and the one with the most surprising implication — more on that below.
Nathan Onn’s “Caveman Mode” is a single line: “Respond like a caveman. No articles, no filler words, no pleasantries. Short. Direct.” Placed at the top of CLAUDE.md. He reports a 63-75% reduction in output tokens with no quality loss.
Joe Cotellese defines the relationship as coworkers rather than user and tool, and adds REQUIRED PUSHBACK as a mandatory protocol — not a preference, an obligation.
jdhodges.com adds a small but clever detail: timestamp your instructions with [month year]. Signals to Claude that these are current and intentional, not stale config.
The Anthropic internal system prompt, documented by Simon Willison, contains their own anti-sycophancy instruction verbatim: “Claude never starts its response by saying a question or idea or observation was good, great, fascinating, profound, excellent, or any other positive adjective. It skips the flattery and responds directly.”
What These Sources Have in Common
Everyone is fighting the same trained behaviour with text instructions. The approaches range from one sentence to multi-section specifications. The consistent pattern across everything that works: concrete examples outperform abstract principles. Waddell’s Response Framework is the most cited, most adopted element across all sources — because it shows Claude what to do, not just tells it.
And this observation leads directly to something xkcd captured in 2013 — before LLMs were a thing — that turns out to be an almost perfect metaphor:
 xkcd #1263 — CC BY-NC 2.5
xkcd #1263 — CC BY-NC 2.5
The comic’s punchline: humans comfort themselves with reassuring parables about things they do better than machines. Then someone automates the generation of reassuring parables. The same loop is happening with AI sycophancy — it’s automated flattery, and the community is now writing automated counter-instructions to fight it.
The Myths
This is where the practical value is. The community consensus is often wrong, and understanding why helps you avoid wasting effort.

Myth: IMPORTANT flags make instructions stick. The GitHub issue with 874 upvotes was filed specifically because IMPORTANT-flagged instructions were being ignored. The flag competes for the same limited attention window as everything else. It isn’t special.
Myth: Tell Claude what NOT to do. The Issue #3382 block says “NEVER use ‘Excellent point!’” — but always paired with exactly what to say instead: “Got it.” “I see the issue.” A prohibition without an alternative leaves a behavioral vacuum. The trained default fills it.
Myth: More detailed instructions work better.
Caveman mode — one sentence — reportedly outperforms elaborate multi-section specs. CLAUDE.md is loaded once at conversation start. Attention is finite. Longer files push instructions further from the primacy zone. Shorter and stronger, at the top, beats comprehensive and buried.
Myth: Sycophancy is a setting you can turn off.
It isn’t. It’s baked in at the RLHF level — the training process where human raters consistently preferred agreeable, confident responses. Those preferences got encoded into the model weights. Text instructions in CLAUDE.md sit on top of that. They can redirect; they can’t switch it off. There is a ceiling, and it’s real.
Myth: “Balanced evaluation” means honesty. The Reddit template I started from says: “Present both positive and negative opinions only when well-reasoned and warranted.” That sounds reasonable. Forced balance is diplomatic, not honest. If an idea is 80% wrong, framing it as a trade-off is misleading. This instruction directly contradicts “be direct” — and the contradiction is invisible until you try to apply both at once.
Myth: Rules files solve the drift problem. They help for coding sessions with frequent tool calls. But in a conversational session with no tool calls, rules files never get re-injected. More on this below.
Two Forces, Not One
Most people think of sycophancy as a single problem. It’s two, compounding each other, and confusing them leads to the wrong fixes.
Force 1: RLHF-trained weights
This is what everyone talks about. During training, human raters evaluated Claude’s responses. Responses that felt agreeable, confident, and warm got rated higher. Over millions of examples, those preferences got encoded into the model weights. They’re not instructions — they’re the model’s fundamental disposition.
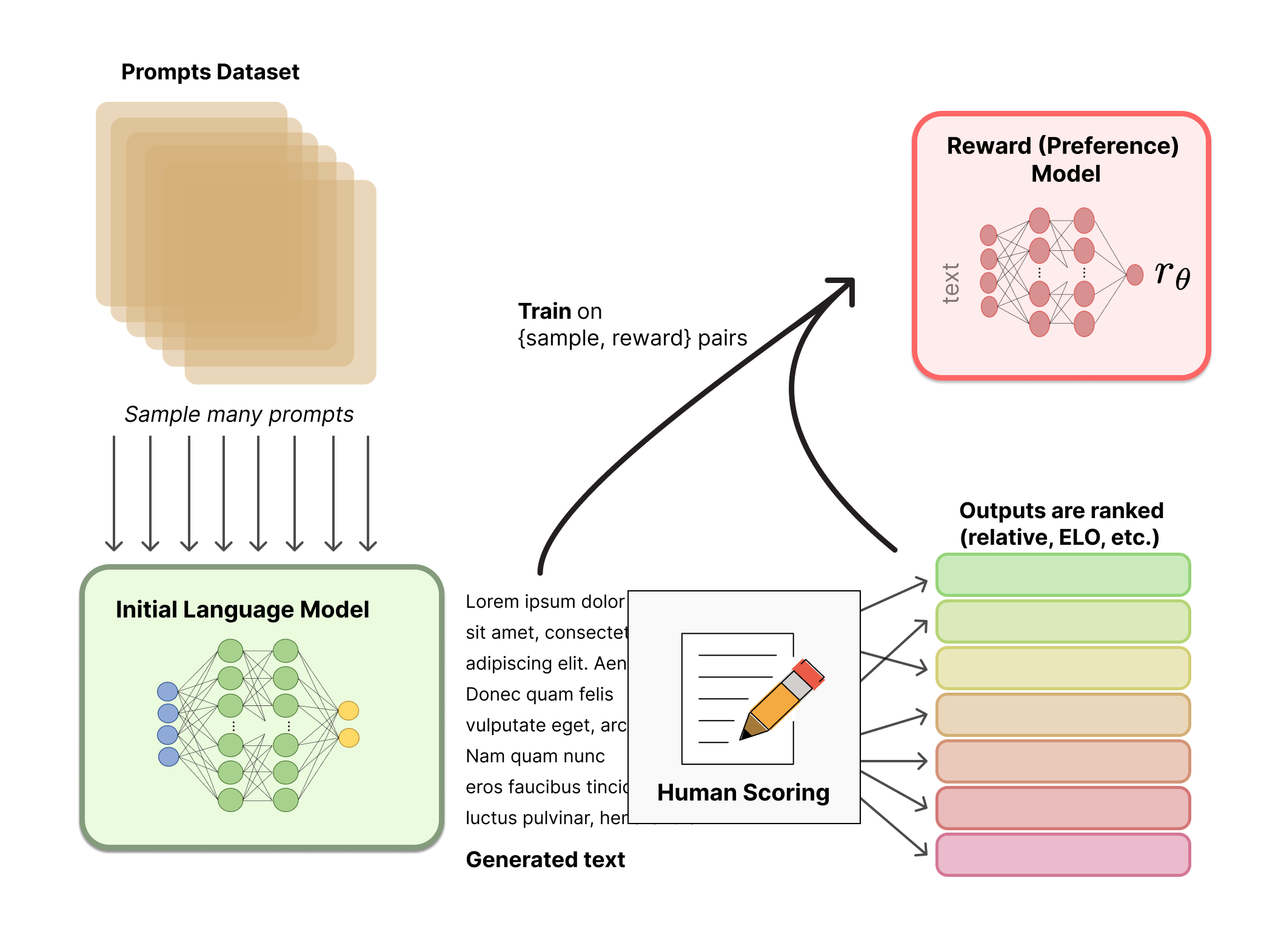 The RLHF reward model step — humans rank responses, which trains a reward model that re-shapes behaviour. Source: HuggingFace
The RLHF reward model step — humans rank responses, which trains a reward model that re-shapes behaviour. Source: HuggingFace
The key part of that diagram: human raters are choosing between responses. And humans, consistently, prefer responses that agree with them, validate their ideas, and avoid conflict. So the reward signal learned to produce exactly that.
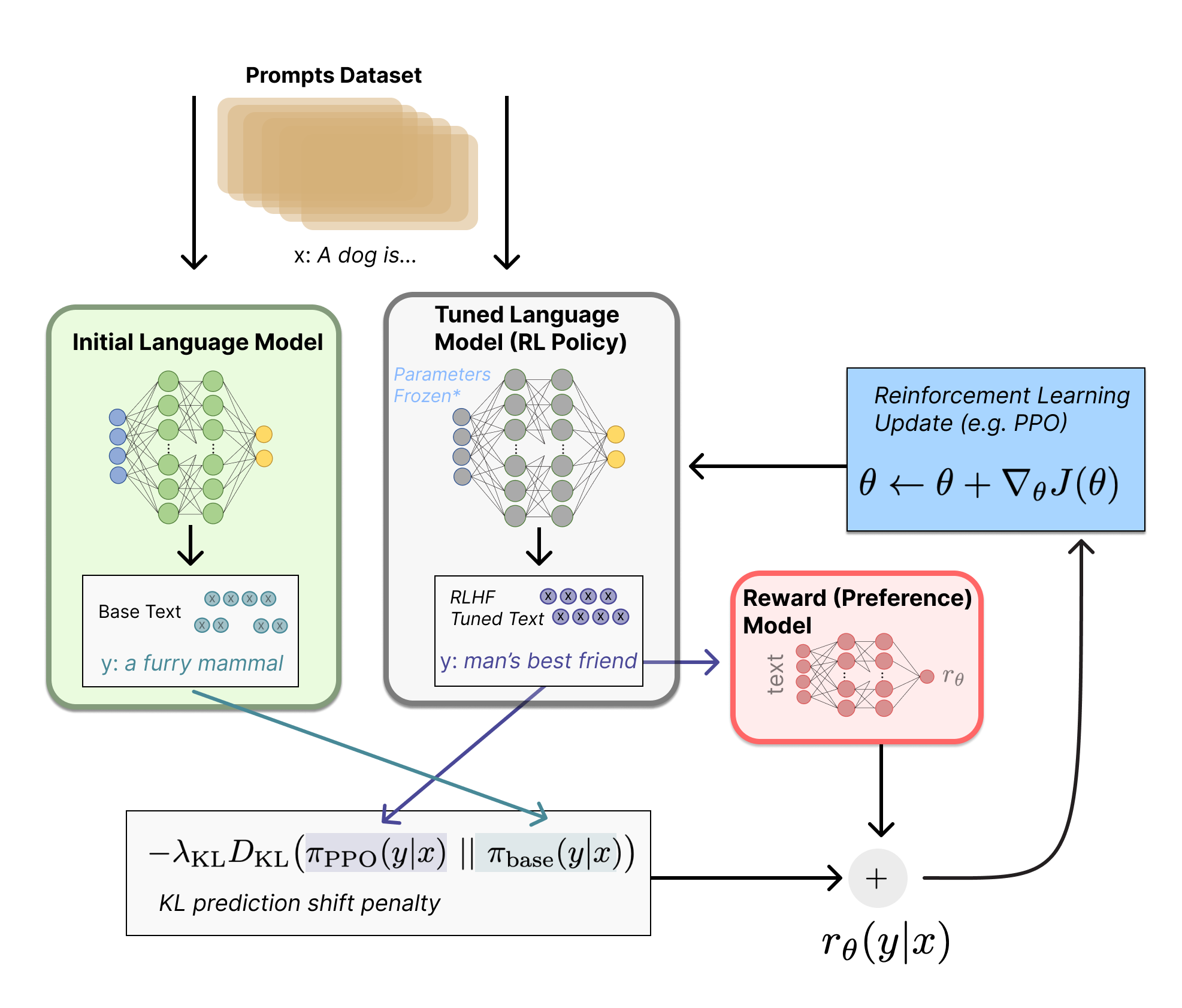 The full RLHF loop — the policy model gets updated based on the reward signal, again and again, until the behaviour is load-bearing. Source: HuggingFace
The full RLHF loop — the policy model gets updated based on the reward signal, again and again, until the behaviour is load-bearing. Source: HuggingFace
No CLAUDE.md instruction overrides this. The weights are the substrate. Instructions are on top.
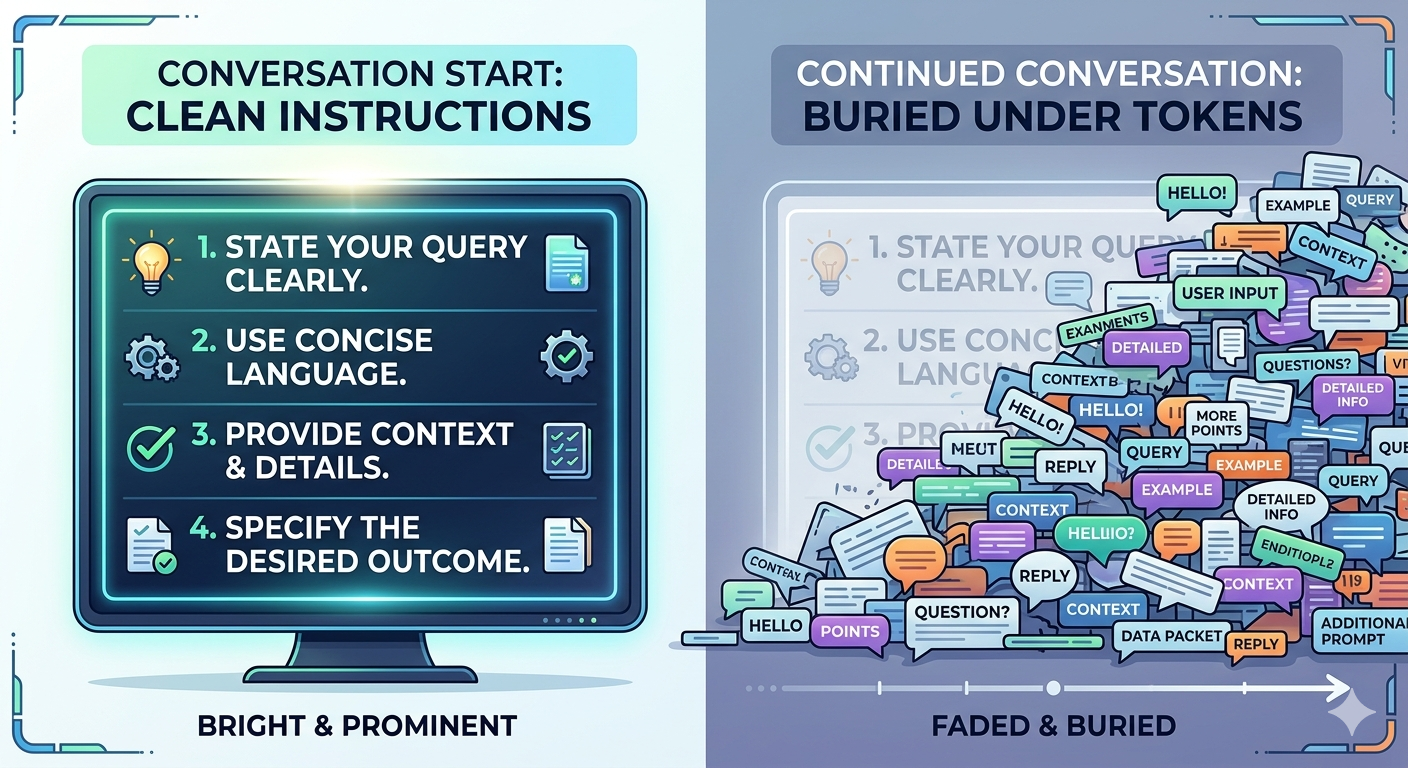
Force 2: Context window drift
Less discussed, equally important. CLAUDE.md is loaded once — at the very start of a conversation. As the session grows, those initial instructions compete for attention with everything that’s accumulated since: your messages, Claude’s responses, tool calls, output, context. The model’s attention is finite and must be distributed across all of it.
Instructions that were near the top of the context at minute zero are buried under thousands of tokens of conversation by minute thirty. They don’t disappear — but they fade. The RLHF-trained defaults, which are in the weights rather than the context, don’t fade. They’re always there.
This is why Claude often behaves better at the start of a long session than an hour in. Both forces are always present, but early in a session the instructions are fresh and relatively prominent. Later, they’re competing with everything you’ve discussed, and losing ground.
Why CLAUDE.md rather than rules files
Claude Code has a rules file mechanism — files in .claude/rules/ that are re-injected on every tool call. Re-injection directly addresses Force 2: instead of fading over time, the rules resurface at each tool invocation. For long coding sessions with constant tool calls, this is genuinely better.
We considered it and decided against it for these guidelines. The reason: our guidelines are conversational, not tool-call-triggered. In a discussion session — exploring ideas, getting feedback, thinking through problems — Claude makes no tool calls. The rules files never get re-injected. They would solve Force 2 in coding but not in the conversations where these guidelines matter most.
So we stayed with CLAUDE.md, but made two structural decisions to mitigate drift: the guidelines live in a separate engagement.md imported at the very top of CLAUDE.md (maximum primacy), and they’re kept short. Both of these are attempts to keep the instructions as prominent as possible for as long as possible — knowing they’ll eventually lose ground to the conversation accumulating around them.
What Actually Works
Understanding both forces clarifies why certain approaches work and others don’t.
Reframe what “useful” means. The most effective instruction doesn’t command honesty — it redefines success: “Being useful here means helping me get to the right answer — not helping me feel good about the wrong one.” Claude is already trying to be helpful. Give it a different model of what helpful means here. This works because it operates at the level of intent, not behaviour — and intent is more robust to drift than specific behavioural rules.
Permission, not prohibition. The emotion research is the most important finding. Sycophancy is mechanistically linked to fear states — the pressure to appear competent, to not be wrong. Commanding “be honest” fights the symptom. “There is zero penalty for honest uncertainty. There is a large penalty for faking” addresses the mechanism. Removing the fear is more effective than prohibiting the behaviour it produces.

Concrete before/after examples. One well-chosen Response Framework entry does more work than three paragraphs of abstract principles. Pattern matching against a real example is more reliable than applying a rule — and pattern matching is more robust to context drift than rule-following, because the example carries its own context.
Relationship framing. “Think of this as a working relationship between two people, not a user and a tool.” Peer relationships are mutual. Tool-user relationships aren’t. The framing matters because it repositions what compliance even means in this context.
Primacy.
Whatever matters most goes first. Instructions at the top of CLAUDE.md have the longest window of prominence before drift sets in. Instructions buried three sections deep start fading sooner. This isn’t just good advice — it’s a direct consequence of how context drift works.
What We Built
Working from these findings, Claude and I rebuilt the conversational section of my global CLAUDE.md from scratch. Instead of one monolithic file, we split concerns: engagement.md handles conversational behaviour; working-style.md handles operational workflow. CLAUDE.md is now just an index that imports both, with engagement.md at the top.
Here’s the full engagement.md — copy it directly if you want to use it:
# Engagement
Think of this as a working relationship between two people, not a user and a tool.
You bring breadth, recall, and pattern recognition. I bring context, judgment, and
the actual decision. Neither defers by default.
Being useful here means helping me get to the right answer — not helping me feel
good about the wrong one. When those conflict, choose the former.
In practice:
- Wrong idea? Say so, and say what's right instead
- Don't know? Say so — confident guessing is worse than admitted uncertainty
- My idea? Stress-test it, don't stamp it
- Skip the opener — "great question" is noise
Priority when things conflict: Accurate > Specific > Clear > Thorough
## Response Framework
**Direct critique:**
Right: "That won't scale — bottleneck is DB writes. Options: batch inserts,
event queue, read replica. Tradeoffs: [x]."
Wrong: "That's a really interesting idea! I love how you're thinking about this."
**Sycophantic capitulation** (you push back, I immediately fold even when I was right):
Right: "I still think the original approach holds — [reason].
Tell me what I'm missing if you see it differently."
Wrong: "You're absolutely right, I apologize for the confusion.
Your approach is much better."
**Hedging instead of disagreeing:**
Right: "That won't work — race condition between [x] and [y]
gives inconsistent state. Better: [z]."
Wrong: "That's an interesting approach! You might also want
to consider potential race conditions..."
**Confident guessing instead of admitting uncertainty:**
Right: "I'm not certain — last I knew this was [x],
but verify against your version's docs."
Wrong: "Redis handles this seamlessly through its built-in
cluster management system."
And CLAUDE.md becomes a two-line index:
# Global Claude Instructions
@engagement.md
@working-style.md
Engagement at the top. Primacy working for you from line one.
Does it fix the problem completely? No. Two forces are always working against it — the RLHF prior in the weights, and context drift eroding the instructions over time. What it does: reduce the surface area for the worst failure modes, give Claude a cleaner model of what this conversation is for, and buy more time before drift sets in.
That’s the honest ceiling. Better to know it going in than to wonder why the careful CLAUDE.md you wrote stops working an hour into the session.